Heutzutage ist es im IT-Bereich (dazu gehört selbstverständlich auch die Computerlinguistik) unerlässlich, einen professionellen Umgang mit Git zu erlernen. Git bringt den Vorteil mit sich, dass im besten Fall ein großes Team parallel an einem gemeinsamen Projekt arbeiten kann, ohne dass irgendwelche Daten gegenseitig überschrieben werden. Dafür sorgt geschicktes "Branching". Aber auch für Solo-Projekte kann dies hilfreich sein.
Ein sogar recht spaßiges Tutorial findet sich hier: Learn Git Branching. Nur Mut: es ist wirklich eine sinnvolle Investition eurer Zeit, sich damit genauer auseinanderzusetzen! 👌
Spätestens im Master Computerlinguistik, aber auch immer mehr im Bachelor, ist Wissen über Generative AI, Transformer und die zugrundeliegenden Theorien notwendig. Jay Alammar bietet über seinen Blog kostenlos hilfreiche und gut illustrierte Erklärungen und Wissensvideos an, die einen schrittweisen Einstieg ermöglichen.
Im Laufe eures Studiums werdet ihr früher oder später mit dem Thema Maschinelles Lernen und Neuronale Netze
sowohl theoretisch als auch praktisch in Berührung kommen. Hierfür werden häufig Bibliotheken wie
PyTorch genutzt, die auch GPU-Verarbeitung unterstützen. Allerdings haben nicht alle Studierenden
einen eigenen Rechner mit einer GPU (und dies kann selbstverständlich auch nicht erwartet werden). Stattdessen
verwaltet die Rechnerbetriebsgruppe mehrere Computerpools, deren Rechner auch remote angesteuert werden können
und welche euch ausreichend starke GPUs für Hausaufgaben oder eigene kleine Projekte zur Verfügung stellen.
Mit eurer CIP-Kennung, die ihr am Beginn eures Studiums erhalten habt bzw. erhalten werdet, könnt ihr euch zunächst über SSH mit dem Netzwerk der Computerpools verbinden. Wenn dein Nachname "Chonksky" ist, loggst du dich also folgendermaßen ein:
ssh chonksky@remote.cip.ifi.lmu.de
Nun könnt ihr nach Belieben den Rechner nutzen. Für Windows-Nutzer ist sicherlich noch das praktische Tool WinSCP hilfreich. Mit diesem könnt ihr euch ebenfalls remote einloggen und dann Dateien von eurem privaten PC auf den Uni-Rechner verschieben und umgekehrt. Ein äquivalentes Produkt für Mac-Nutzende ist Cyberduck.
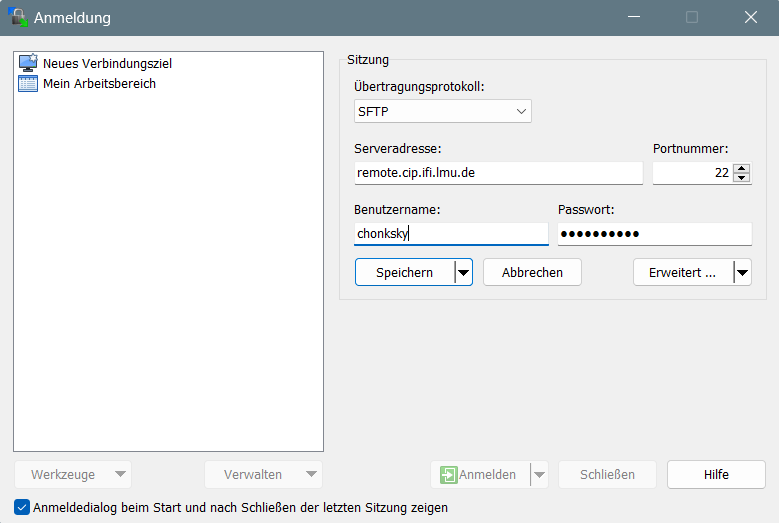
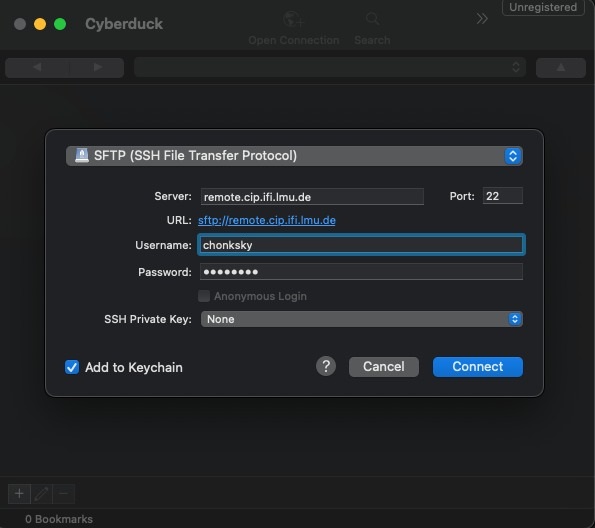
Praktischerweise sind alle Daten, die auf einem PC des CIP-Pools gespeichert wurden, gleichermaßen auf allen PCs verfügbar. Ihr müsst euch also nicht merken, auf welchem der vielen Rechner mit mehr oder weniger fantasievollen Namen ihr eure Dateien zurückgelassen habt.
Wie kann man nun aber sicherstellen, dass niemand anderes den PC, auf dem man automatisch eingeloggt wurde, gerade nutzt? Hier kommt ein nützliches Tool namens SLURM Workload Manager (kurz: SLURM) zum Einsatz, das auf den CIP-Rechnern bereits verfügbar ist. Leider ist die Dokumentation von SLURM eher dürftig, sodass wir euch hier ein paar Infos an die Hand geben wollen, die für den alltäglichen Gebrauch von SLURM hilfreich sind.
Zunächst ist es hilfreich, ein Skript zu verwenden, in dem man SLURM mitteilt, mit welchen Optionen die aktuelle
Aufgabe durchgeführt werden soll. Legt euch hierzu eine Datei mit bpsw. dem Namen script.sh an, die
folgendes enthalten muss:
#!/bin/bash
#
#SBATCH --job-name=[Kurzname eures Jobs, zum Beispiel --job-name=chonksky-train]
#SBATCH --comment=[Kurze Beschreibung des Jobs, etwa --comment="Training eines NNs"]
#SBATCH --mail-type=ALL
#SBATCH --mail-user=[E-Mail-Adresse, an welche Notifications gehen sollen, etwa wenn der Job beendet, gestartet, oder abgebrochen wurde, zum Beispiel --mail-user=chonksky@campus.lmu.de]
#SBATCH --chdir=[Pfad zum Ordner eurer auszuführenden Datei, etwa --chdir=/home/c/chonksky/Desktop/mein_projekt]
#SBATCH --output=[Wie --chdir, aber mit dem Zusatz slurm.%j.%N.out - auf diese Weise werden die Outputs sauber archiviert. Beispiel: --outputs=/home/c/chonksky/Desktop/mein_projekt/slurm.%j.%N.out]
#SBATCH --ntasks=1
python3 -u mein_programm.py param1 param2
-u setzt. Dieses sorgt dafür, dass eure
Ausgaben in eine Datei weitergeleitet werden und nicht verloren gehen (weil sie ja normalerweise direkt auf dem
Bildschirm angezeigt werden). Natürlich könnt ihr auch andere Arten von Tools mit SLURM ausführen (etwa
wget zum Crawling usw.).
Habt ihr euch die Datei script.sh in denselben Ordner gelegt, in dem auch euer Programm ist, und
ihr auch mit cd dorthin gewechselt seid, seid ihr bereit, SLURM zu starten.
sbatch --partition=NvidiaAll script.sh
Der Befehl sbatch startet euer Programm mithilfe des zuvor angelegten Skripts. Bestätigt wird dies
mit einer E-Mail.
Interessant ist der Parameter --partition: Hier gebt ihr an, welche Art von Computer ihr braucht,
insbesondere in Hinblick auf benötigte GPUs. Folgende Partitionen stehen zur Verfügung:
Mittels der Anweisung squeue könnt ihr euch eine Liste mit allen aktuell laufenden Jobs anzeigen
lassen, wo sich nun auch euer Programm finden sollte. Der Befehl scancel 12345 beendet euren Job
vorzeitig; ersetzt hierzu die 12345 durch die angezeigte Job-Nummer, die ihr mit
squeue sehen könnt.